의료 이미지 segmentation 에서 가장 많이 활용되는 모델은 UNET으로, 주로 인코더에서 CNN 계열 모델을 붙이고 디코더에 UNET으로 De-convoluioning 하는 Up-sampling 과정을 통해 학습시킨다.
UNET 후속 모델인 UNET++, UNET3+ 도 있으나, 동일한 데이터로 실험해본 결과 성능의 큰 차이는 없었다. (다만, 모델 사이즈가 조금 작아져서 light 해지는 결과는 있었음.)
UNET은 2015년에 소개된 이후 약 10년간 많이 활용되었지만, 최근 제안되는 모델에 비해 성능이 많이 떨어지는 결과가 많았음.
UNET 구조
semantic segmantation SOTA 모델 성능비교
Dataset 별 성능 비교 결과
모델 결과비교
전체 모델 구조
In our study, we utilized a parameter, F (filter size), to modify the depth of convolutional layers. Through comprehensive experimentation, we determined that a model incorporating 17 filters serves as an optimal representation of a smaller model, while a model incorporating 34 filters represents a larger model effectively.
Res Block
The Residual block , first introduced in ResUNet++ paper [10], is the first component in our novel DUCK. Its purpose is to understand the small details that make a polyp. While using multiple small convolutions is usually a good idea, having too many can mean that the network has difficulty training and understanding what features to look for. We use combinations of one, two, and three Residual blocks to simulate kernel sizes of 5x5, 9x9, and 13x13.
Midscope Block
Widescope Block
Our novel Midscope and Widescope blocks use dilated convolutions to reduce the parameters needed to simulate larger kernels while allowing the network to understand higher-level features better. They work by spreading the nine cells that would typically be in a 3x3 kernel over a larger area. These two blocks aim to learn prominent features that only require a little attention to detail, as the dilation effect has the side effect of losing information. The Midscope cell simulates a kernel size of 7x7, and the Widescope simulates a kernel size of 15x15.
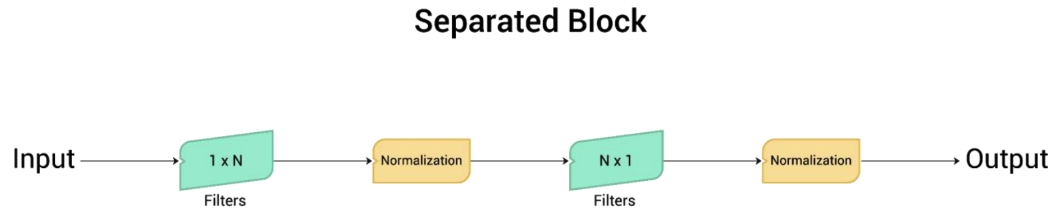
Seperated Block
The Separated block (Figure 5) is our third way of simulating big kernels. The main idea behind it is that combining a 1xN kernel with an Nx1 kernel results in a behavior similar to an NxN kernel. However, this method encounters a drawback related to the concept known as "diagonality". Essentially, diagonality implies the capacity of a convolutional layer to capture and sustain spatial details linked to diagonal patterns in an image, a feature intrinsic to the structure of a conventional NxN convolutional kernel. It retains these diagonal elements owing to its bi-dimensional characteristics, enabling it to capture spatial connections in both vertical and horizontal directions, which also encompasses diagonal aspects.
Yet, the distinctive processing approach of separable convolutions (1xN followed by Nx1), where filters operate on one dimension at a time, potentially obstructs their capacity to efficiently encode diagonal features. This leads to the so-called "loss of diagonality". Such diagonal relationships can prove useful for detecting specific intricate patterns or shapes within an image, hence the other blocks are designed to compensate.
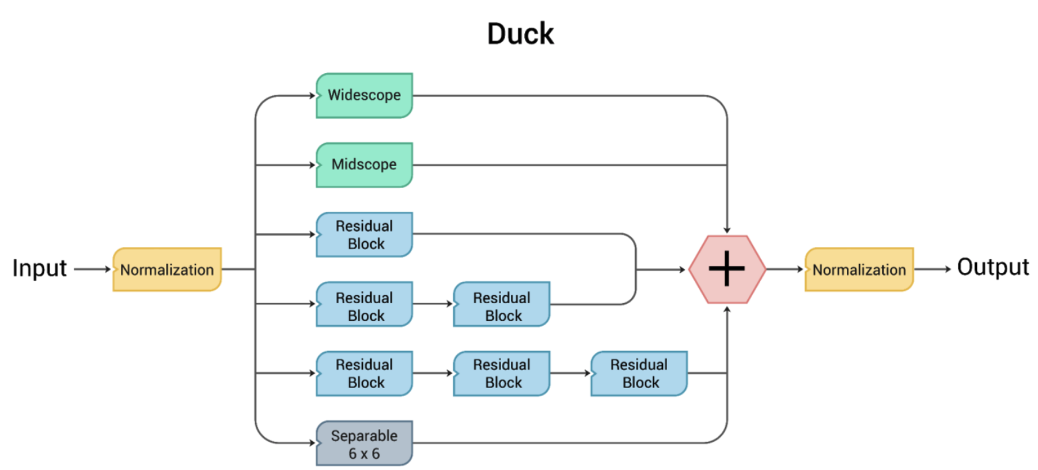
DUCK is our novel convolutional block that combines the previously mentioned blocks, all used in parallel so that the network can use the behavior it deems best at each step. The idea behind it is that it has a wide variety of kernel sizes simulated in three different ways. This means that the network can decide how to compensate for the drawbacks of one way to simulate a kernel over another.
Having a variety of kernel sizes means it can find the general area of the target while also finding the edges correctly. We incorporated a one-two-three combination of residual blocks based on empirical observations suggesting no significant performance gains from multiple instances of Midscope, Widescope, and Separable blocks. Essentially, the computational resources required for these additions did not justify the marginal improvements in results. The result is a novel block that searches for low-level and high-level features simultaneously with auspicious results.